










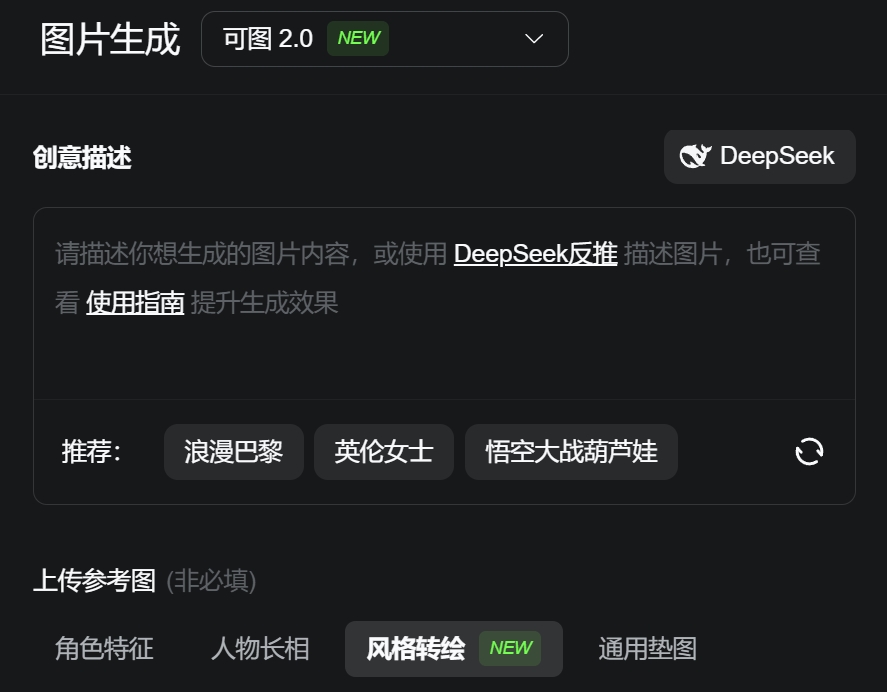


可图AI是什么?
一、技术架构与核心能力突破
二、功能创新与用户体验
三、行业应用与市场表现
四、竞品对比与行业地位
五、未来规划与挑战
总结
相关导航













Copyright©2023-2025 AIGC工具导航 津ICP备2022006237号-2 津公网安备12011002023007号 互联网违法和不良信息举报渠道
津公网安备12011002023007号 互联网违法和不良信息举报渠道
Copyright©2023-2025 AIGC工具导航 津ICP备2022006237号-2津公网安备12011002023007号 互联网违法和不良信息举报渠道