EchoMimic – 阿里推出的开源数字人项目,赋予静态图像以生动语音和表情

什么是EchoMimic
EchoMimic是由阿里巴巴蚂蚁集团推出的一款基于音频驱动的肖像动画生成工具,属于AI视频模型的一种,该技术于2024年对外发布并开源。其核心功能是将静态的图片转化为具有生动语音和表情的数字人物,在娱乐、教育、虚拟现实、在线会议等诸多领域带来全新的可能性,为数字人技术的发展掀开了新的一页。
例如,通过这一技术,只需提供一张人脸照片和一段音频(如说话或唱歌音频),就能生成口型动作匹配的说话或唱歌视频,可用于制作口播视频或趣味唱歌视频等。
EchoMimic的功能特点
多模态驱动与丰富表现
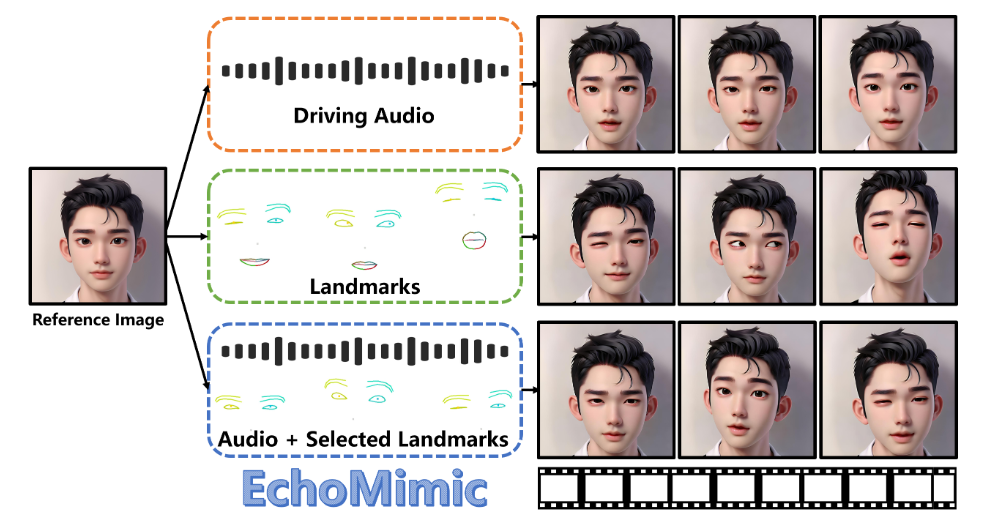
- 音频驱动动画,唇音同步:EchoMimic能够分析音频波形,精确地生成与语音同步的口型和面部表情。无论是唱歌还是说话场景,都能生成口型动作与语音完美匹配的视频,大大提升了视频的真实性和表现力。这一功能可以将静态图像转化为具有逼真动态表现的视频内容,就像是图像中的人物自己在发声一样。
- 面部特征融合:采用面部标志点技术,能够捕捉并模拟眼睛、鼻子、嘴巴等关键部位的运动。这些面部标志点实际上是面部图像上用于表示关键特征和结构(如眼睛、鼻子、嘴巴等位置)的特定点,可以帮助计算机视觉算法更好地理解和分析面部表情和动作。通过将这些部位运动融入动画,大大增强了动画的真实感,使得生成的数字人表情更加自然、细腻,而不是生硬的机械运动。
- 多模态学习:结合音频和视觉数据,运用多模态学习方法。这个过程中,它不只是简单地结合两者,而是深度融合了音频中的语音节奏、韵律等特征与视觉上的面部表情、姿态等信息。通过这种方式,提升了动画的自然度和表现力,使得数字人的 anim内分泌科运动更加流畅,整体表现更加符合人类的真实行为模式,大大减少了动作的不协调感和机械感。
- 多种驱动方式相结合:除了单纯的音频驱动动画以外,还支持姿势数据驱动动画,并且创新性地支持音频和姿势的混合驱动。这一特性让数字人的动作更加多样化,通过姿势数据或者混合驱动的方式,数字人能够做出更多自然流畅且富有表现力的动作,不仅丰富了数字人的表现形式,也增加了动画的创作空间。
广泛的适用性
- 跨语言能力:支持中文普通话和英语等多种语言。这意味着不同语言区域的用户都能利用该技术制作动画。无论音频内容是哪种语言,EchoMimic都能够根据语音内容准确地生成与之匹配的口型和面部表情动画,为全球用户提供服务,在国际化场景下具有很强的适应性。
- 风格多样性:能够适应不同的表演风格,包括日常对话、歌唱等多种形式。在不同的风格场景下,如轻松风趣的日常聊天或者富有激情的歌唱表演,EchoMimic都可以根据相应的音频情感和节奏特点,生成合适的面部表情和口型动画,满足了用户制作不同风格动画的广泛需求,为其提供了丰富的应用场景选项。
便捷操作相关特性
- WebUI界面操作:为了简化操作流程,EchoMimic提供了直观的Web用户界面。用户无需编写代码,只需通过简单的参数调整,即可轻松创建数字人动画。这种低门槛的操作方式使得更多的用户(包括非专业技术人员)能够轻松上手,体验数字人动画创作的乐趣,降低了数字人动画制作的技术门槛,极大地提高了创作效率。
- 本地离线生成支持(windows平台):F5 – AI社区为Windows用户提供了EchoMimic的免费本地离线整合包。用户可以通过简单三步(下载、安装、使用)就能够在本地离线免费生成数字人。这克服了一些在线生成可能面临的网络不稳定、数据隐私安全等问题,同时也方便用户根据自己的需求随时创作数字人动画,不需要依赖网络连接即可获得较好的使用体验。
EchoMimic的应用场景
娱乐产业革新
- 虚拟主播和虚拟歌手:在娱乐领域,EchoMimic可以用于创造虚拟主播、虚拟歌手等。它可以根据预先设定的人物形象或者输入的人物照片,结合提供的音频(如歌声或者直播话术等)来生成逼真的动画效果。虚拟主播可以24小时不间断工作,降低了人力成本的同时提高了直播效率。虚拟歌手则能够在演唱过程中展现出逼真的面部表情和口型变化,为观众提供全新的娱乐体验,并且可以根据不同风格的歌曲做出相应的表情和动作变化,增强表演的感染力和观赏性。
- 影视与游戏制作:在电影、电视剧和游戏等的制作过程中,EchoMimic可以用来生成角色对话场景下的面部动画。它能根据配音音频精确地生成角色的口型和表情变化,大大提升制作效率并减少人工对口型的工作量。同时,在游戏中还可以为角色定制更加丰富逼真的表情系统,例如根据不同的游戏情节(如角色受到惊吓、惊喜等),配合相应的语音效果来生成自然的面部表情,让游戏角色看起来更加生动真实,增强玩家的代入感。
教育领域创新
- 虚拟教师:在教育领域,可作为虚拟教师进行应用。它能够通过录制好的讲解音频,配合合适的教师人物形象,生成与之同步的动态教学视频。在教学过程中,虚拟教师可以根据讲解内容展现丰富的面部表情(如强调知识点时的严肃表情、提问时的疑惑表情等),并且保持良好的口型同步效果,提供互动式学习体验,让学生更有沉浸感,仿佛置身于真实的课堂之中。这种虚拟教师可以根据不同的教学内容、教学风格进行定制,适应不同学科和年龄阶段的教学需求。
虚拟现实体验提升
- 增强沉浸感的虚拟角色创建:在虚拟现实(VR)环境中,EchoMimic可以创建逼真的虚拟角色。当用户在VR场景中与这些虚拟角色进行交互时,角色能够根据用户的语音输入做出准确的表情和口型回应,使虚拟角色看起来更像真实的人类个体,增强用户在虚拟现实场景中的沉浸感。比如在VR社交或者VR多人协作游戏中,通过EchoMimic技术让每个虚拟角色都能具有生动的表情交流,让整个交互过程更加自然和真实。
在线会议高效协作
- 线上会议发言人虚拟形象生成:在在线会议场景中,EchoMimic可以为发言人生成虚拟形象并且保持与音频同步的口型动画。即使参与者处于远程状态,也能看到发言人逼真的面部表情和口型变化,从而使在线会议更具专业性和互动性。这样在远程交流中,一方面能够提高沟通效果,避免因为没有面部表情而导致的交流信息缺失;另一方面,相比于单纯的音频会议或者低质量的视频会议,发言人的虚拟形象能够更好地传达情绪和态度等非言语信息,提升会议整体效果。
数字营销新手段
- 品牌IP塑造与推广:可以为品牌打造个性化专属的IP,将品牌的精神、理念、文化等要素集中到一个虚拟数字人上。例如,某时尚品牌创建一个虚拟模特,通过这个虚拟模特展示品牌的最新款式服装和配饰,利用数字人逼真的表情和动作效果,吸引年轻消费者的关注,增强品牌的吸引力和互动性。此外,音乐平台可以创建虚拟歌手来吸引年轻用户的关注和参与,增加平台的活跃度和用户粘性,这为数字营销带来了新的流量增长点,为企业提供了一种创新的营销载体形式。
EchoMimic的技术原理
EchoMimic的工作原理主要基于深度学习技术。
音频与视觉因素的解析与处理
- 音频特征提取:首先,EchoMimic对输入的音频进行深入分析,利用先进的音频处理技术提取出语音的节奏、音调、强度等关键特征。例如,通过语音识别技术把语音内容转换为数字模型能够理解的信号特征,这些音频特征包含了语音的韵律信息、语速快慢、音高变化等,这对于后续与面部表情的协调非常关键。如果是唱歌的音频,还能识别音准、音符长度等相关特征,以便生成与唱歌动作相匹配的动画,就像是声乐教师根据唱歌者的声音特点来指导表情动作一样。
- 面部标志点定位:通过高精度的面部识别算法,EchoMimic能够精确地定位面部的关键区域,如嘴唇、眼睛、眉毛等的面部标志点。这些标志点不仅仅是面部部位的定位,还包含对这些部位在不同表情下状态的理解。例如,在微笑时嘴唇如何弯曲、眼睛如何眯起来等表情相关的关键位置信息捕捉,为后续的动画生成提供基础,就像艺术家在作画时先勾勒人物轮廓和关键特征一样重要。
动画的预测与生成
- 面部动画生成:结合音频特征和面部标志点的位置信息,EchoMimic运用复杂的深度学习模型来预测和生成与语音同步的面部表情和口型变化。它可能使用类似神经网络的深度学习算法来构建音频特征到面部动作之间的映射关系。例如,表情是愤怒时,根据音频中紧张高亢的节奏以及愤怒语音的音频特征,模型会通过之前学到的映射关系,让数字人的面部做出挑眉、瞪眼、紧咬嘴唇等表情,并且确保表情和说话的口型是同步进行的。多模态学习策略在这个过程中发挥了很大作用,大量的音频 – 视觉数据联合学习使得这种映射关系更加准确和自然,保证了生成的动画在视觉上逼真并且在语义上与音频内容高度一致。
- 生成对抗网络(GAN)的作用:为了确保视觉效果的逼真性,EchoMimic可能采用了生成对抗网络(GAN)技术。GAN由生成器和判别器两部分组成,生成器负责生成看似真实的面部动画,判别器则负责判断生成的动画是否真实,通过两者不断地对抗训练,使得生成器生成的动画越来越逼真,无限接近真实的面部运动和表情变化。比如判别器可以基于大量真实的人类表情和口型样本数据来评判生成动画的真实性,如果发现不真实的地方(如不合理的表情过渡或者口型不匹配),就反馈给生成器进行调整,直至生成的动画在视觉上几乎无法被识别出是由机器生成的为止。
创新训练策略
- 多模态数据的双重训练:EchoMimic采用了多模态学习策略和创新的训练方法,其核心在于能够独立地或者结合地使用音频和面部标志点数据进行训练。这意味着在训练过程中,模型既能单独从丰富的音频数据中学习语音韵律与情感和面部动作的关联,也能从面部标志点数据里学习不同表情对应的面部肌肉运动模式。然后,在多模态联合训练下将两者的知识进行结合优化,生成更加逼真和自然的动态肖像。例如,单独的音频训练可能教导模型在高声调时应该产生怎样的口型张开程度,面部标志点单独训练则可以让模型领会不同表情下眼睛、眉毛的位置变化规律,两者结合后就能生成一个更加自然、精确地反映不同语音和情感的面部动画。
- 预训练与实时处理:项目使用了在大量数据上预训练的模型,这使得EchoMimic能够快速适应新的音频输入,并实时生成面部动画。预训练模型是在海量的音频 – 面部动画数据之上进行训练得到的,积累了丰富的知识模式,例如不同语言、不同语音风格下的动画生成模式等。当遇到新的输入音频时,预训练模型能够根据已有的知识快速启动并调整到合适的动画生成模式,并且根据实时的音频输入进行动态的调整,从而保障动画的及时性和准确性,就像一个经验丰富的厨师在面对新食材时,能迅速根据自己的厨艺经验做出美味的菜肴一样。
EchoMimic的发展前景
技术优化与提升
- 内容表达精确性和丰富度提高:随着深度学习模型的不断优化,EchoMimic的发展重心之一将是持续提高数字人物动画的质量。未来在生成动画时,对于人物的表情、手势等细节方面能够有更精确的表达。例如在眼神交流和微表情传达上能够更加准确地反映出数字人的“情绪”状态。不仅能实现与人的多媒体交互更加自然,例如在对话场景下数字人的眼神能够跟踪说话者的位置,并根据对话内容做出不同的细微表情反应;此外,在多人物场景下,数字人物之间的互动表情和动作也将更加丰富,使得整体呈现更加贴近真实复杂人际互动的状态。
- 多种模态融合提升:继续深入探索多模态学习。除了现有的音频和面部标志点数据的融合,未来会尝试融合更多模态信息,如身体姿态、手部动作等相关信息到动画生成系统中。这将使数字人在表现上更像真实人类,能够做出更多种类、更为复杂的自然动作,像真人在不同场景下的整体身体语言表达(如开心时跳舞的姿势、聆听时歪头的动作等)。而且不同模态信息之间的融合也将更加精确,减少不同动作之间出现不协调或者冲突的情况。
应用领域的扩张
- 云边端协同计算优化效能:随着云边端协同计算的发展,EchoMimic的应用效能将得到极大提升。在当前情况下,一些硬件性能较差的终端设备在运行EchoMimic生成数字人动画时可能会受到限制。然而,借助云边端协同计算,EchoMimic相关的计算负载可以被合理地分配到云端、边缘端以及终端设备上。云端具有强大的计算资源,可以承担较为复杂的模型运算等任务;边缘端可以进行一些预处理和缓存等操作;终端设备主要用于显示输出以及处理部分较为简单的交互指令。这样就能够实现让EchoMimic的应用不再受限于终端硬件的性能,能够广泛应用于各种硬件设备平台,大大拓宽了应用范围,例如在低性能的移动设备或者物联网设备上也能流畅运行并生成高质量的数字人动画。
- 广泛应用于更多行业:如今已经在娱乐、教育等多个领域彰显了应用价值,未来有望进一步在医疗、客户服务、广告等更多行业取得深入发展。在医疗领域,比如可以利用数字人进行健康知识普及的视频制作,数字人以医生形象生动地讲解疾病预防知识,配合准确的口型和表情,更加吸引观众;在客户服务领域,数字人可作为智能客服的视觉形象,增强与客户交互时的亲和力;在广告行业,可以创作出生动的数字人代言人,根据广告文案做出相应的表情和动作变化,吸引消费者的眼球实现更好的广告效果,乃至于更多人们尚未完全探索或者新兴的行业领域,都会因EchoMimic而焕发出新的可能性。
开放式创新与社区贡献
- 开源生态带动二次开发:由于EchoMimic已经开源,这将吸引全球众多开发者参与到该技术的优化与扩展当中。开源意味着代码和技术文档对外公开,不同的开发者可以根据自己的创意和需求对EchoMimic进行个性化的改进和功能扩展。例如,一些开发者可能开发出适合特殊场景(如军事模拟训练中的虚拟角色、考古复原中的古代人物形象展示等)的衍生版本;还有可能会开发更简洁易用的操作界面或者更高效的算法优化插件等。通过开源社区的合作与共享,EchoMimic将会不断衍生出新的工具和应用。
- 跨平台整合与交互特性增强:在开源社区影响下,未来很可能会与更多的平台和技术进行整合。比如与新兴的虚拟现实和增强现实平台进行深度整合,无缝嵌入到这些虚拟环境中成为其中顶级的交互内容创建工具;与更多的人工智能框架(如计算机视觉框架、语音处理框架等)协作,提升在不同平台上处理多种数据的能力,如在不同操作系统、不同品牌硬件之间实现更好的互操作性。这将进一步提升EchoMimic的通用性和兼容性,使其在多元技术生态环境下有更强的生命力和发展潜力。






 津公网安备12011002023007号
津公网安备12011002023007号