StreamingT2V – PicsArt推出的可生成长达2分钟视频的模型

一、StreamingT2V的定义
StreamingT2V是一种由PicsArtAI研究团队推出的创新型文本到视频(Text – to – Video,T2V)生成模型。它能够根据用户输入的文字描述来生成视频内容,其独特之处在于能够生成长度可达1200帧(约2分钟)的长视频,并且保证视频在时间上的连贯性、帧与帧之间过渡的平滑性,以及与输入文本描述的紧密贴合性。
例如,当输入“广阔战场上,冲锋队员在奔跑”这样的描述时,StreamingT2V可以生成相应场景的视频内容,在整个视频中,冲锋队员的奔跑动作连贯,画面中的场景从始至终保持与战场这一描述相符的特征,不会出现场景跳跃或者人物动作不连续等突兀情况。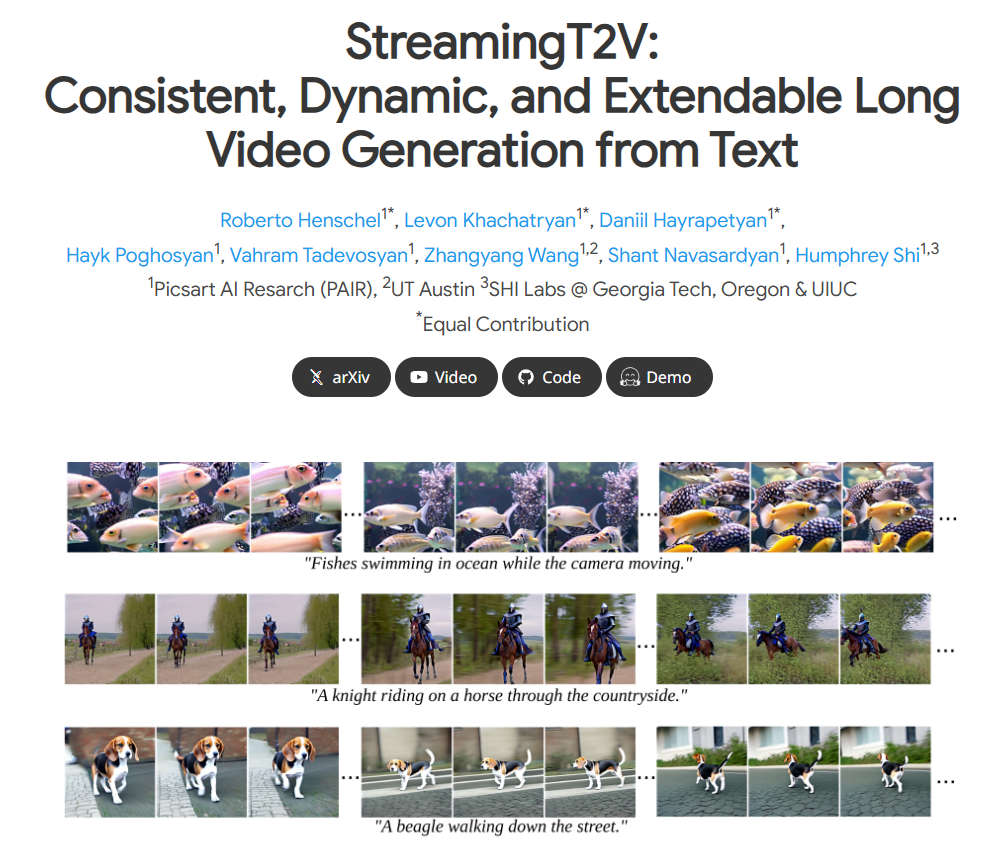
二、StreamingT2V的特点和优势
(一)长视频生成能力
- 突破时长限制 在传统的文本到视频生成技术中,往往只能生成较短的视频,例如16帧或24帧的短视频。然而,StreamingT2V能够生成80、240、600、1200帧甚至更多帧的长视频,这极大地拓展了文本到视频生成技术的应用范围。这一突破主要得益于其创新的技术框架,不再受限于传统技术的瓶颈问题[]。
- 可扩展性 理论上,StreamingT2V的视频长度不局限于1200帧,可以进一步扩展,这为那些对视频时长要求较高的应用场景(如电影制作、长时长的教育视频等)提供了巨大的潜力。研究人员也在不断探索和优化其技术,以逐步实现无限长视频的生成目标[]。
(二)高质量输出
- 高动态效果 该模型生成的视频具备丰富的动态效果,画面生动且毫无停滞或重复之感。从每一帧画面的细节到整体的视频效果,都能够很好地展现出场景中事物的运动状态,让观众仿佛身临其境,体验感非常强。
- 时间一致性 确保整个视频从开始到结束在时间上保持连贯统一。在生成长视频过程中,不会出现视频片段之间的不自然切换或突兀的过渡现象。通过引入特定的技术模块(如条件注意力模块等)来协调每一帧之间的关系,使得观看视频时感觉像是一个连贯拍摄的整体,比如在表现一个连续的运动场景(如跑步比赛)时,运动员的动作、周边环境(如观众的欢呼、赛场的标识等)都能持续且流畅地展现。
- 紧密的文本对齐 视频内容与输入的文本描述紧密相关联并准确呈现文本中的各种元素,例如场景、动作、人物关系以及故事情节等。理解文本的语义层面并以此来构建视频画面的各个部分,使得最终生成的视频完全符合用户的文本输入描述预想。例如输入“清晨,一只好奇的小猫在花园里探索五颜六色的花朵”,视频就会完美地呈现出清晨的花园中,小猫进行探索花朵这一动作等场景要素。
- 高质量的图像帧 生成的初始视频具有256×256的分辨率,并且可以通过后续处理提升至720×720,整个过程注重每一帧图像的质量把控,即使是在较长的视频当中,每一帧的画面依然能够保持清晰与细腻,不会出现因为视频变长而画面变得粗糙、模糊的问题。
(三)技术的灵活性
该模型的有效性不依赖于特定的文本到视频模型。这意味着随着文本到视频技术基础模型的改进优化(例如新的预训练模型的出现、模型结构的优化等), StreamingT2V生成的视频质量有进一步提升的空间。其本身具有一种可兼容和可扩展的特性,方便与其它先进的技术成果进行有机整合,以强化自身的性能表现[]。
三、StreamingT2V的应用场景
(一)电影和媒体制作领域
- 复杂情节创作 在电影制作方面,导演和编剧可以输入详细的剧情描述,让StreamingT2V生成一些复杂场景的视频片段作为预演内容或者参考素材,比如宏大的战争场面、幻想世界中的奇异生物互动场景等。这样可以在前期节省人力、物力和时间成本,快速可视化故事概念,有助于创作者之间更好地沟通创意、理解剧本,加快制作流程[]。
- 预告片制作 制作电影或电视剧预告片需要从大量素材中选取精华部分进行拼接组合,而且在正式拍摄之前可能很难获取到实际的素材片段用于预告片制作。利用StreamingT2V,可以根据电影宣传文案或者剧情关键信息迅速生成相关的高质量视频片段,通过剪辑这些片段制作成吸引观众的预告片。
(二)游戏开发行业
- 动态场景与故事视频生成 游戏开发者可以借助StreamingT2V生成游戏内的动态场景,如描绘游戏角色所处的特定环境(如阴暗神秘的城堡内部、充满科幻元素的外太空空间站等)。同时,对于游戏背景故事的推广或者游戏教程内容,也可以通过输入相关的文字描述来生成相应的视频,增强故事叙事性和教导的直观性,使玩家能够更深入地理解游戏世界观和玩法规则。
- 增强游戏沉浸感和互动性 通过生成符合游戏情节和风格的短视频,当玩家达到游戏中的特定阶段或者完成特定任务时,播放这些特定的视频片段以加深玩家的沉浸感,增强游戏体验的连贯性;或者作为互动内容的一部分,根据玩家的不同选择输入相应的文字生成不同走向的视频结果展示给玩家。
(三)教育培训领域
- 教学视频制作 教育工作者可以输入课程内容的文字描述来生成教学视频,例如科学实验过程、历史事件的场景重现等。在学习化学实验流程时,可生成详细展示实验仪器使用步骤、药品反应现象等内容的视频,对于抽象的理论知识也可以通过形象化的视频表达来辅助理解,这样能够提供更连续、全面的学习材料给学生,有效提升学生的学习效果。
- 模拟实验视频生成 对于一些存在危险或者昂贵设备才能进行的实验,如生科领域中的基因编辑实验、化学中的放射性物质实验等,直接实际操作实验成本高且风险大。利用StreamingT2V可以根据实验原理、步骤等文本描述生成模拟实验视频来满足教学研究需求。
四、StreamingT2V的技术原理
(一)总体架构及工作流程
StreamingT2V的工作流程主要分为三个阶段:初始化阶段、流式生成阶段和流式细化阶段[]。
- 初始化阶段 在这个初始步骤中,会使用预训练的文本到视频模型(例如Modelscope等)来合成一个最初始的视频块,通常这个初始视频块是一个16帧的较短视频序列。它是整个长视频生成的起始点,为后面的过程奠定了基础。
- 流式生成阶段 此阶段是自回归的长视频生成核心过程,StreamingT2V在这个阶段借助于条件注意模块(CAM)和外观保持模块(APM)来生成长视频的后续帧。
- 条件注意力模块(CAM)
- 短期记忆机制:CAM可以视为短期记忆的保障,它利用此前一个视频块中的最后几帧(如20帧)作为输入资料。例如前一个视频块是一组奔跑的人群画面,这最后几帧人群的奔跑姿态、所处环境等细节特征都会被作为重要输入。
- 特征提取与注入:先通过图像编码器对这最后几帧进行逐帧的编码,从而得到与之对应的特征表示。然后,将这些特征送入一个浅层编码器网络(这个网络会初始化自主模型的编码器权重)中进行进一步的编码处理。完成编码后,将这些提取出的特征表示注入到StreamingT2V的UNet每个长程跳跃连接处,便于借助前一个视频块中的内容信息生成新的视频帧。并且,这样做还可以保证在生成新帧时不受之前结构、形状方面的约束。这种特征注入方式能够让新的视频帧与前面的内容自然流畅地衔接起来,实现了流畅自然的视频块之间的过渡,同时保留了视频中的具有高速运动特征等重要元素。
- 外观保持模块(APM)
- 长期记忆功能实现:APM起到长期记忆的作用,从初始图像(也就是所谓的锚定帧)当中提取出高级的场景以及对象等特征,例如视频伊始画面中标志性建筑的特征、主要人物的外形特征等。
- 确保一致性:把这些提取出来的特征应用于全部视频块的生成流程当中。这有助于在自回归的视频生成进程里,维持对象和场景等特征的连贯性。由于现有部分相关技术往往只针对前一个视频块的最后一帧进行条件生成处理,容易忽视自回归过程中的长期依赖关系,但APM通过利用初始图像中的全局信息,有效地克服了这个问题,可以更好地捕捉到自回归生成过程中的长期依赖性。
- 条件注意力模块(CAM)
- 流式细化阶段 为了提升以及优化已经生成的视频质量,在这个阶段会使用高分辨率的文本到视频模型对之前生成的视频进行一种自回归增强处理。并且在这个过程中采用随机混合方法来提高视频的整体质量和分辨率。在处理时,模型先将低分辨率的视频划分成为多个长度为24帧的视频块,而且这些视频块相互之间是存在重叠部分的(例如8帧重叠)。从第一个块开始,先采样噪声,对于后续的每一个块,按照特定规则和前一个块重叠帧的噪声进行结合,并通过这样的自回归方式不断地对视频进行增强优化。
(二)技术模块协作原理
StreamingT2V中的各个技术模块相互协作是实现高质量长视频生成的关键所在。
- 短期记忆与长期记忆协同 条件注意力模块(CAM)的短期记忆机制与外观保持模块(APM)的长期记忆功能相互配合。CAM负责处理局部的短时间内的视频块连接优化,保证视频块间的平滑过渡,比如处理连续几个视频块之间人物动作的连贯性。而APM从整体的宏观角度把握视频特征的一致性,保证从最初的初始帧开始,整个视频中的核心场景元素、人物外观等特征在长时间的视频生成过程中不会发生混乱或者丢失。
- 生成与细化环节衔接 在前面提到的流式生成阶段生成视频帧后,进入流式细化阶段,这个阶段的自回归增强处理是在前者生成基础上进行精度和质量提升。这种生成 – 细化的环节衔接有助于逐渐优化视频质量,类似于先搭建一个框架,再逐渐对框架内的每个元素进行精细化加工。比如在生成初期构建出一个基本场景轮廓,后续再针对场景中的元素(如花草树木的细节、人物的表情等)进行逐渐清晰化和完善。
五、StreamingT2V与其他技术的比较
(一)与传统文本到视频技术的比较
- 视频时长突破 传统的文本到视频技术大多只能生成非常短的视频,例如16帧或者24帧的短视频。而StreamingT2V能够生成长达1200帧(约2分钟)的长视频,并且理论上有进一步扩展视频长度的能力,在电影、教育等时长要求较高的领域,传统技术远远无法满足需求,而StreamingT2V具有明显的优势。
- 视频质量表现差异
- 在传统技术生成视频时,尤其是长视频的生成,常常面临视频帧之间过渡生硬、时间连贯性差的问题,例如场景切换时的跳跃感等。然而StreamingT2V通过条件注意力模块(CAM)和外观保持模块(APM)保证了在视频帧的平滑过渡和时间连贯性,避免了那种生硬连接、场景转换不协调等不好的观看体验。
- 在图像质量上,传统文本到视频技术当视频长度变长时,画面质量容易显著下降;而StreamingT2V注重帧级别的图像质量,在整个长视频生成中能使每一帧皆保持清晰、细腻的良好结果。
(二)与其他竞品(同类文本到视频技术)的比较
- 一致性方面
- 像Text – To – Video – Zero(T2V0)和ART – V这样的竞品,采用的是文本到图像扩散模型,它们往往缺乏全局推理,在生成视频时会出现不自然或重复的动作。而StreamingT2V的外观保持模块(APM)能够利用初始图像中的全局信息,通过合理的技术手段保持视频中的场景和对象在长时间内的一致性,避免视频过程中出现不合理的变化或者重复,动作连贯性更自然[]。
- MTVG这种竞品通过无需训练的方法将文本到视频模型转换为自归 方法,但它在视频块之间采用强一致性先验,导致运动量非常低且大部分背景是静态的。相比之下,StreamingT2V借助条件注意力模块(CAM)能够使视频在保持一致性的同时有丰富的动态效果而不会太过死板[]。
- 运动特征表现方面
- 一些竞品在处理运动场景时存在局限性,如Gen – L在生成重叠短视频然后聚合的时候可能导致视频停滞并且质量下降。StreamingT2V通过自身的模块协作机制,如条件注意力模块对前一视频块运动特征的有效利用,能够很好地处理运动场景,即使是长视频中的运动画面也能展现流畅自然的效果,不会出现停滞或运动不自然的情况[]。
- 一些对前一个视频块的最后一帧进行条件生成的竞品,没有充分考虑到整体的长期依赖性,StreamingT2V的外观保持模块(APM)可以很好地弥补这一不足,保证了视频中的动作场景等运动特征在整个视频生成过程中的连贯性和合理性[]。













Copyright©2023-2025 AIGC工具导航 津ICP备2022006237号-2 津公网安备12011002023007号 12377违法和不良信息举报中心 互联网违法和不良信息举报渠道
津公网安备12011002023007号 12377违法和不良信息举报中心 互联网违法和不良信息举报渠道